Building a Data Lake with AWS


Building a Data Lake with AWS
Hi Peepz,
It officially the Day 3 of the #DevOpsAllStarsChallenge .
#DevOpsAllStarsChallenge is a challenge that aims to equip devops engineers with on demand skills required of them.

Project Architecture Diagram
Project Overview
A data lake is a centralized storage system for large amounts of data, including structured, semi-structured, and unstructured data. Data lakes are used to store data in its original format, and can be used for analytics, machine learning, and other business intelligence.
In this post I will work you through how to levearge AWS services like AWS Glue and Amazon Athena to run and query the data stored on S3 bucket and also send the processed to S3 bucket
Project Structure
nba-data-lake/
├── policies/
│ ├── iam-role.json
├── src/
│ ├── setup_nba_data_lake.py
├── .env
├── .gitignore
├── cleanup.py
├── README.md
└── requirements.txt
Prerequisites
Before you begin make sure you have these:
Prerequisites
1. Sportsdata.io Account
Sign up for a SportsData account and acquire your NBA API Key by following their onboarding instructions.
2. AWS Account
Set up your AWS account:
Create a free-tier AWS account here.
Log in to the AWS Management Console.
Create a unique IAM user with programmatic access.
Generate an Access Key and Secret Key for authentication.
Initialize the AWS CLI
aws configure
3. Python Environment
Ensure Python version 3.7 or higher is installed:
python3 --version
pip --version
pip install -r requirements.txt
If not , download it from the official website.
4. Environment Variables
Configure the .env file with the following values:
AWS_BUCKET_NAME=your_bucket_name
SPORTS_DATA_API_KEY=your_api_key
NBA_ENDPOINT=https://api.sportsdata.io/v3/nba/scores/json/Players
AWS_REGION=your_region
Walkthrough
Clone the repository:
git clone https://github.com/Kasnoma/NBA-Data-Lake.git
cd nba-data-lake
Run this command to execute the script:
python3 src/setup_nba_data_lake.py
Verify that the resources have been created in your AWS management console:
S3 Bucket: Confirm the creation of a bucket containing the raw NBA data in JSON format under the folder
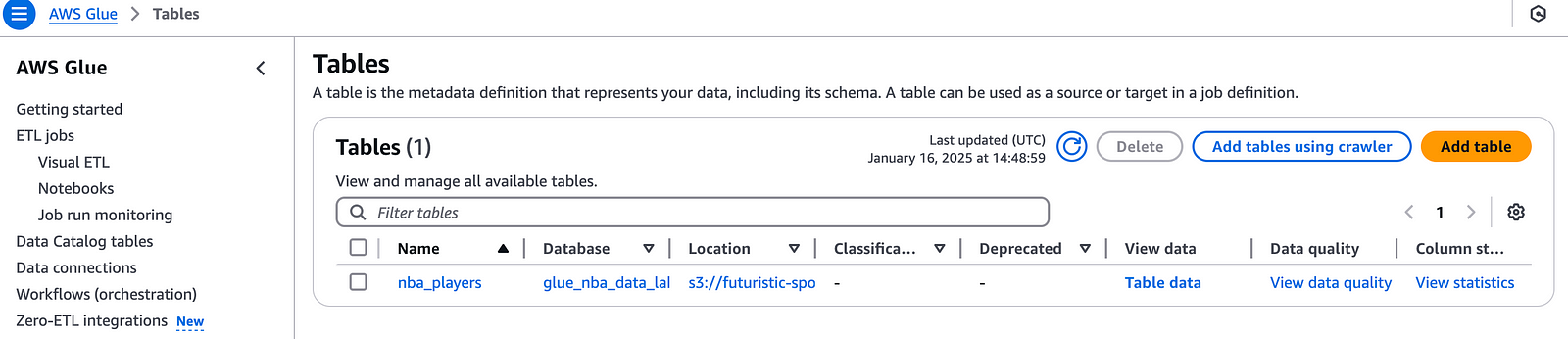
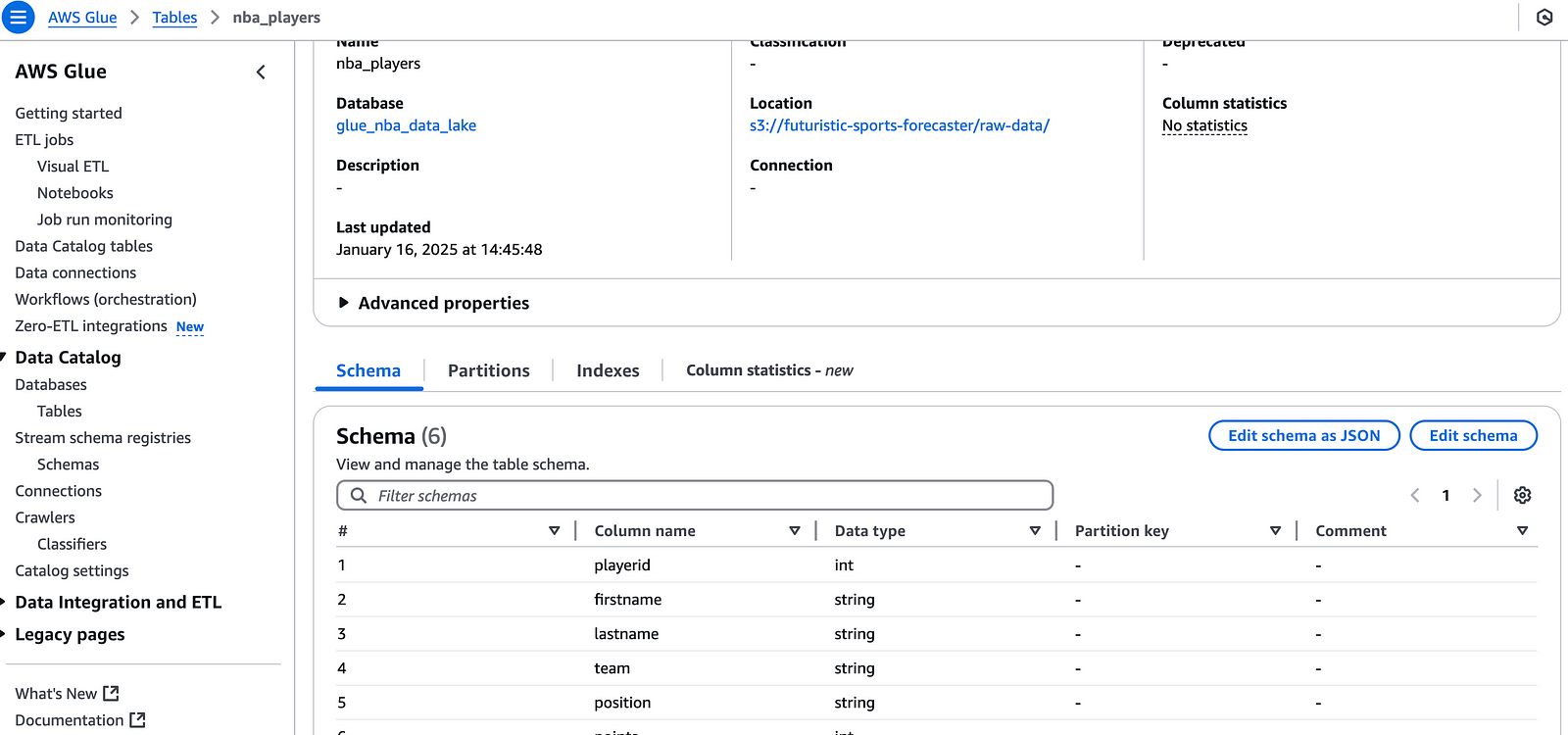
raw-data/nba_player_data.json.Glue Database and Table: Ensure the database (
glue_nba_data_lake) and table (nba_players) exist in AWS Glue.
Query Data in Amazon Athena:
Navigate to Amazon Athena in the AWS Management Console, and run the following SQL query:
SELECT FirstName, LastName, Position, Team
FROM nba_players
WHERE Position = 'PG';

Conclusion
Transform raw sports data into actionable insights with just a few steps. Feel free to experiment with additional queries and integrate the data lake with advanced analytics tools such as Amazon QuickSight for visualizations.
Checkout my post on medium